How to pick a vibe coding project you can actually finish
You don’t have time to build a platform. You have time to ship one useful thing. Here’s how to pick a vibe coding project that fits 6 weeks and actually makes it to production.

It's possible to fail my vibe coding class in week 0.
Not because students can’t code. Not because they can’t prompt. Not because they aren’t “technical enough”.
They fail because they pick a project that cannot be completed in the time budget, then spend six weeks discovering that fact one sharp edge at a time.
Let’s do the math you’re trying to avoid:
- 6 weeks
- ~8 hours/week total, including 2 hours in class
- ~48 hours end-to-end
Forty-eight hours is not “a small startup.” It’s not “a MVP.” It’s not “a platform.”
It’s one useful thing that works.
If you internalize that, you’ll ship. If you don’t, you’ll build a bridge to nowhere.
The selection rule: one thin vertical slice
Your project should be exactly one primary use case / user flow / problem:solution pairing.
That’s the “thin vertical slice” idea in plain English: pick a user journey that starts with real input and ends with a real output, and build only the minimum to complete that path. (Agile people have been yelling about vertical slices for a long time for good reason.)
If you can’t write your project as a single sentence of the form:
“When X happens, I want Y to be easier/faster, by doing Z.”
…you do not have a project yet. You have vibes.
What “thin” actually means in practice
- One user (you, or a single role persona)
- One dataset (already accessible)
- One workflow
- One output format
Everything else is a non-goal, or at best, a stretch goal.
Non-goals are the secret weapon
A good project proposal has a bigger “will not build” section than “will build”. Because the universe will happily expand to fill your ambitions.
So you write non-goals like you mean them:
- “No user accounts.”
- “No roles/permissions.”
- “No notifications.”
- “No multi-tenant anything.”
- “No mobile.”
- “No ‘connect to any data source’.”
- “No ‘plugin system’.”
- “No “make it agentic”.”
This is not pessimism. This is how you help yourself stay focused, prioritize, and ship something finished.
No platform building (a.k.a. don’t build your own shovels)
There is a specific failure mode that hits smart people:
They decide that before they can build the product, they must first build a framework that would make building the product easier.
They will not, in fact, build the product.
Call it “premature generalization.” Call it YAGNI. Call it “I wanted to feel productive without taking product risk.” Martin Fowler’s write-up on YAGNI exists because this is a timeless trap.
For my class (and anyone else getting started vibe coding):
- You are not building a framework.
- You are not building a reusable platform.
- You are not inventing a new architecture.
- You are not writing an SDK.
- You are not designing a general solution.
You are building a tool that solves one problem for one role.
The xkcd rule: automate something you already do
A lot of “good projects” are just: I do this annoying thing repeatedly; I want to do it less.
That’s not boring. That’s great scoping.
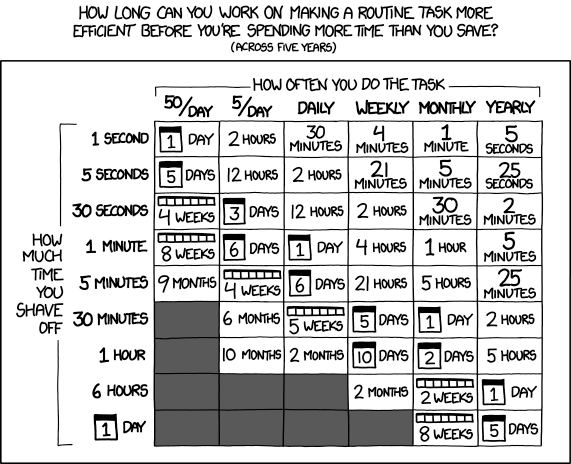
xkcd #1205 (“Is it worth the time?”) is the best one-panel product strategy guide ever published: automation only wins when the time saved pays back the time spent building it. In the case of the panel, it's over a 5 year period of time, but with the rate of change in AI, your tools likely won't live that long so you have to be even more aggressive in deciding what you will and will not build.
Your class constraint is brutal: 48 hours. So your best projects are usually:
- repetitive task
- clear inputs
- clear outputs
- measurable time saved
- minimal dependencies
The three categories you should avoid
1) Anything that requires scraping
Scraping turns a project into a never-ending argument with:
- auth flows
- bot defenses
- HTML changes
- rate limits
- legal/terms ambiguity
- data cleaning
Even if you can do it, it’s the wrong kind of complexity for a six-week build. Before someone jumps down my throat, yes this can absolutely be done using tools like Firecrawl, but this article is written for a beginner audience, and I don't think they should be doing scraping as their first project.
If you need external data, prefer:
- official APIs
- CSV exports
- your own database servers
- static dumps you control
2) Anything where an LLM is exposed to the “lethal trifecta”
If your project involves an LLM, you need to learn one core security idea:
When you combine:
- untrusted input (documents, email, webpages, user text)
- tool access (database queries, file access, email sending, money movement)
- automatic execution (the model can trigger tools without a human gating step)
…you get a system that can be coerced into doing the wrong thing.
Simon Willison has been writing about this pattern (including the “lethal trifecta” framing), and it shows up in real-world prompt injection failures.
This isn’t theoretical. OWASP ranks prompt injection as the #1 risk for LLM applications. And the UK NCSC has been blunt that prompt injection is fundamentally different from SQL injection because LLMs don’t naturally separate “instructions” from “data”—they describe LLM systems as “inherently confusable”.
For this class, the easiest way to win is: don’t build something where the model can take actions on your behalf from untrusted text.
LLMs are fine when they are:
- drafting
- summarizing
- transforming text you already trust
- working in a sandbox
- producing output that a human approves
3) Anything with no obvious existing solution
Your goal is to learn how to build, not to invent something novel.
If you can’t point to an existing product and say, “my version is simpler and narrower for my exact workflow,” you’re signing up to discover requirements instead of implementing them.
Discovery is expensive. Implementation is teachable. Pick implementation.
A simple project filter that works
If your idea can’t pass these, kill it fast:
Scope
- Can I describe the core workflow in 5 steps or fewer?
- Can I build a “walking skeleton” version in week 1?
Data
- Do I already have the data in a form I can access today?
- If the data disappears, does the project still make sense?
Dependencies
- How many external systems do I need to integrate?
- If any one integration breaks, am I dead?
Safety
- Is the LLM allowed to “do things,” or only “suggest things”?
- Is there a human approval step before anything irreversible?
Ship-ability
- Can I demo this live in under 2 minutes?
- Can I measure impact (time saved, errors reduced, clarity improved)?
Diagram: what you’re building (and what you’re not)
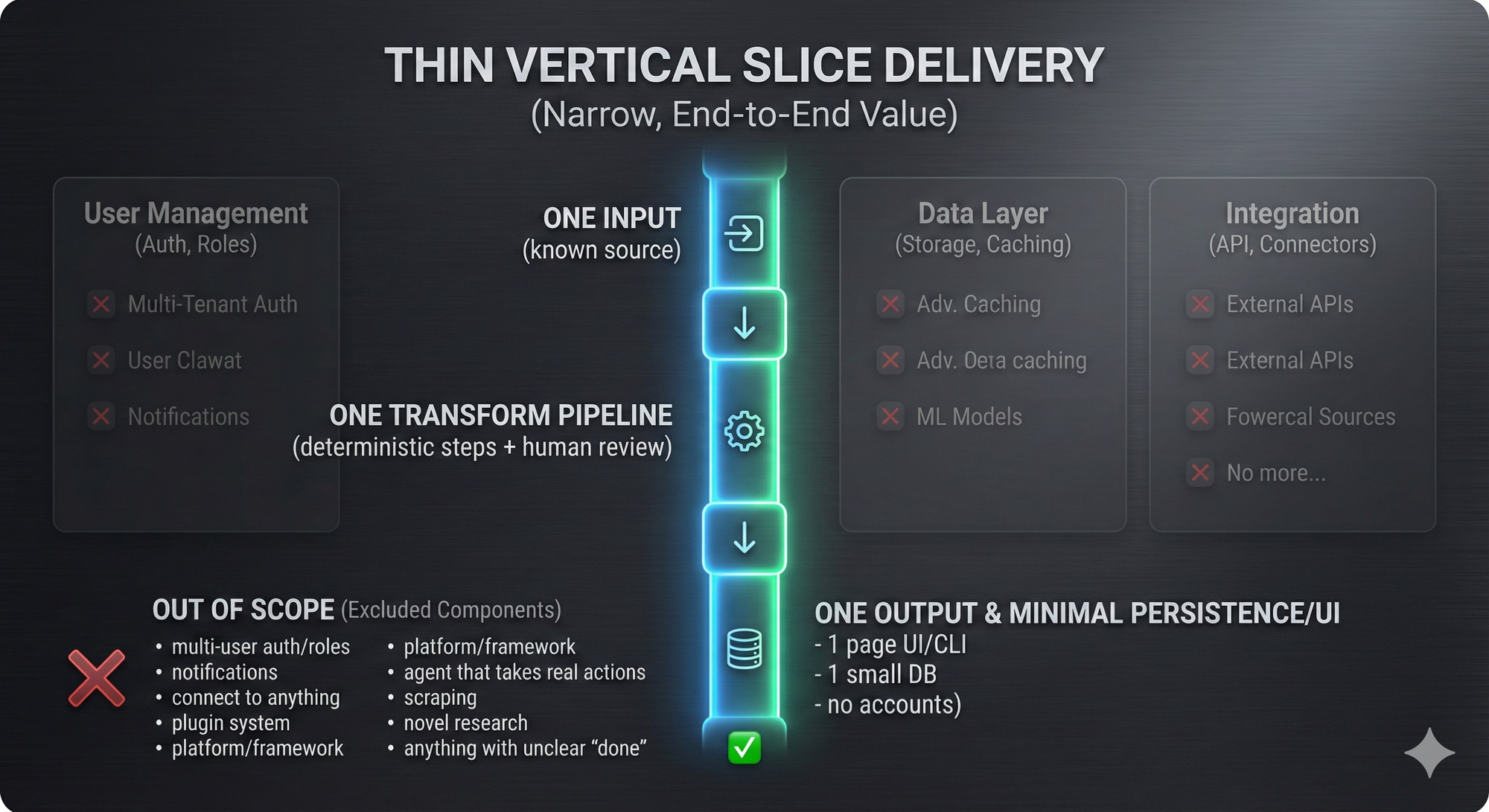
Examples: projects that fit the class constraints
Below are role-aligned ideas that are intentionally narrow. Each is a single slice with explicit non-goals. They're also on a 6 week timeline that aligns with the order in which we teach things in my vibe coding class.
1) Quant research analyst at a 10-person fund
- Project: “PDF-to-signal note generator” for earnings decks
- Thin slice: Upload PDF → extract key sections → produce a standardized 1-page memo template
- Non-goals: No trading execution, no portfolio integration, no live market data
- Data: PDFs you already receive
- Why it fits: deterministic-ish pipeline + human review
- Week-by-week plan
- Week 1 (LLMs + project selection + ship plan):
- 1-page spec: exact memo format + sections + non-goals
- Repo + deploy target + Hello World live
- Decide PDF input path (upload vs file path) and output format (Markdown)
- Week 2 (scoping requests + harnesses + first core flow):
- Implement core flow: upload PDF → text extraction → render memo template
- Add config (env vars) for “section list” + template version
- Write 5 manual QA scenarios (good PDF, scanned-ish PDF, missing section, huge PDF, weird formatting)
- Week 3 (git hygiene + PR discipline):
- PR workflow: “core flow” PR + review checklist (even solo)
- Add formatter/linter; break changes into 5–10 small commits
- Week 4 (refactor + tests):
- Refactor: separate extraction vs parsing vs rendering modules
- Add tests: 3 unit tests (template rendering), 1 integration (PDF→text), optional E2E (upload→memo)
- Week 5 (CI/CD + prod hardening):
- CI: lint + tests on PR; block merge on failure
- Prod safety: file size caps + timeouts + graceful failure messaging
- Add logging + basic error tracking
- Week 6 (docs + launch + demo):
- README: setup + “how to run locally” + known limitations
- Demo: one real earnings PDF → memo in <2 minutes; show CI + tests + deploy
- Week 1 (LLMs + project selection + ship plan):
2) Chief Investment Officer of a family office
- Project: “Manager meeting prep pack”
- Thin slice: Paste agenda + last notes → generate questions + risk checklist + follow-up email draft
- Non-goals: No CRM, no contact syncing, no automatic emailing
- Data: your own notes + pasted text
- Why it fits: output is drafts, not actions
- Week-by-week plan
- Week 1:
- 1-page spec: define “prep pack” sections + strict length limits
- Repo + deploy target + Hello World
- Decide inputs: (agenda text, last notes text) and outputs: (brief + email draft)
- Week 2:
- Build core flow: paste agenda + notes → generate prep pack
- Add config: meeting type (quarterly/new manager) as a simple selector
- Manual QA: 5 scenarios (short notes, long notes, missing agenda, conflicting notes, jargon-heavy)
- Week 3:
- PR discipline: split “prep pack” and “email draft” into separate PRs
- Add repo hygiene + formatting; 10 meaningful commits
- Week 4:
- Refactor: enforce structure (headings, bullet counts) with a rendering layer
- Tests: unit tests for formatting rules; integration test for input parsing
- Week 5:
- CI + deploy pipeline
- Prod safety: PII guardrail (basic detection + warning) + “no-send” explicit non-goal in UI
- Logging + error tracking
- Week 6:
- Docs + demo: agenda+notes → prep pack + email draft; show config + CI + tests
- Launch checklist: include sample input fixtures for repeatable demo
- Week 1:
3) Investor relations at JPMorgan Chase (or any large org)
- Project: “FAQ diff tracker” for quarterly messaging
- Thin slice: Compare last quarter’s FAQ vs this quarter’s → highlight deltas → produce review doc
- Non-goals: No publishing workflow, no approvals system, no stakeholder routing
- Data: two doc versions
- Why it fits: clear input/output, measurable time saved
- Week-by-week plan
- Week 1:
- Spec: define input format (Markdown/doc text) + output report structure
- Repo + deploy + Hello World
- Decide what counts as “delta” (new/removed/edited; numeric changes called out)
- Week 2:
- Core flow: paste/upload doc A + doc B → generate change report
- Config: thresholds for “major change” + numeric-delta detection
- Manual QA: 5 cases (reordered sections, small wording change, big rewrite, number change, formatting noise)
- Week 3:
- PR: split parser/differ vs report renderer; adopt small commits + review checklist
- Add linter/formatter
- Week 4:
- Refactor: isolate diff engine from UI
- Tests: unit tests for diff classification; integration test for doc parsing; optional E2E for upload→report
- Week 5:
- CI + deploy checks
- Prod safety: file size caps + deterministic diff fallback (no LLM required)
- Logging + error tracking
- Week 6:
- Docs + demo: run last quarter vs this quarter → produce review doc; show CI/tests
- Week 1:
4) Investor relations as a service for startups
- Project: “Monthly investor update generator”
- Thin slice: Fill a 12-field form → generate update email + metrics table
- Non-goals: No cap table, no investor portal, no distribution automation
- Data: manually entered metrics (or CSV)
- Why it fits: you can constrain the format hard
- Week-by-week plan
- Week 1:
- Spec: lock the 12 fields + exact email structure + tone rules
- Repo + deploy + Hello World
- Decide storage: none (stateless) or minimal snapshot (one table)
- Week 2:
- Core flow: fill form → generate email + table
- Config: template versions + optional “tone” preset (constrained)
- Manual QA: 5 cases (missing fields, extreme numbers, negative month, pipeline empty, headcount change)
- Week 3:
- Git workflow: PR-based improvements; add formatting + repo standards
- Make 10 meaningful commits; one cleanup PR
- Week 4:
- Refactor: separate validation, computation (deltas), and rendering
- Tests: unit tests for delta math + formatting; integration test for CSV import (if included)
- Week 5:
- CI + deploy pipeline
- Prod safety: spend caps (if using LLM) + strict token/length limits; retries/timeouts
- Logging + error tracking
- Week 6:
- Docs + demo: enter metrics → investor-ready update in <60 seconds; show tests + CI
- Week 1:
5) CEO of a 20-person company
- Project: “Weekly business review pack” from Postgres
- Thin slice: Run fixed queries → render single report page + narrative summary
- Non-goals: No self-serve BI, no arbitrary queries, no permissions model
- Data: your Postgres
- Why it fits: pre-defined queries avoid “build Metabase”
- Week-by-week plan
- Week 1:
- Spec: choose 6–10 metrics + fixed SQL list + report layout
- Repo + deploy + Hello World
- Set up DB connection locally (even if using a sample DB)
- Week 2:
- Core flow: button/CLI runs queries → renders report
- Config: env vars for DB URL + query set selection
- Manual QA: 5 scenarios (DB down, slow query, nulls, empty week, migration mismatch)
- Week 3:
- PR workflow: metrics query changes via PRs; add linter/formatter
- Commit hygiene + one cleanup PR
- Week 4:
- Refactor: query layer vs render layer vs summary layer
- Tests: unit tests for summary formatting; integration test for DB query runner; optional E2E for report generation
- Week 5:
- CI (lint + tests) + deploy on merge
- Prod safety: query timeouts + caching + idempotent report generation
- Logging + error tracking
- Week 6:
- Docs + demo: live DB → report; show CI + tests + deploy; run book note for DB failures
- Week 1:
6) Head of operations for a 2000-person company
- Project: “Incident postmortem assembler”
- Thin slice: Paste timeline + notes → generate postmortem doc + action-item table
- Non-goals: No Jira integration, no auto-ticket creation, no notification routing
- Data: pasted content
- Why it fits: doc generation is shippable and safe
- Week-by-week plan
- Week 1:
- Spec: postmortem template + required fields + non-goals
- Repo + deploy + Hello World
- Decide input structure (timeline format) and output (Markdown)
- Week 2:
- Core flow: paste timeline+notes → generate postmortem doc
- Config: template version + required sections
- Manual QA: 5 cases (missing timestamps, conflicting notes, very long incident, multiple systems, unclear impact)
- Week 3:
- PR discipline + repo hygiene; enforce “green main”
- Add formatter/linter
- Week 4:
- Refactor: extraction (timeline/actions) vs rendering
- Tests: unit tests for table generation + required-section checks; integration test for end-to-end doc build
- Week 5:
- CI + deploy
- Prod safety: validation gates (don’t generate without required fields) + safe defaults
- Logging + error tracking
- Week 6:
- Docs + demo: paste incident notes → postmortem ready; show tests/CI; include sample incident fixtures
- Week 1:
7) Executive assistant for a 100-person company
- Project: “Meeting brief builder”
- Thin slice: Paste attendee list + last notes → generate agenda + reminders + follow-ups
- Non-goals: No calendar write access, no emailing, no contact graph building
- Data: calendar text copied in
- Why it fits: saves real time, avoids lethal trifecta
- Week-by-week plan
- Week 1:
- Spec: define brief structure + exact outputs + strict length limits
- Repo + deploy + Hello World
- Decide input schema (attendees + notes + meeting purpose)
- Week 2:
- Core flow: paste inputs → brief + follow-up drafts
- Config: templates by meeting type (weekly 1:1 vs staff meeting)
- Manual QA: 5 cases (many attendees, sparse notes, long notes, unclear purpose, sensitive info)
- Week 3:
- PR workflow + repo standards; commit hygiene
- Add formatting + linting
- Week 4:
- Refactor: parsing vs templating vs rendering
- Tests: unit tests for formatting/constraints; integration test for generating all outputs
- Week 5:
- CI + deploy
- Prod safety: PII warning + “copy-only” outputs (no send); spend caps if using LLM
- Logging + error tracking
- Week 6:
- Docs + demo: paste inputs → brief + follow-ups in <90 seconds; show CI/tests; run book note
- Week 1:
A “good vs bad” framing (use this as your template)
Good:
“I am building a tool that helps one role do one recurring workflow using one known dataset, producing one output. It explicitly will not do X/Y/Z.”
Bad:
“I am building a platform anyone can use for anything, and it connects to arbitrary data sources.”
If your draft smells like the word “platform,” it’s already on fire. If it smells like "stricter spreadsheet" or "single person multi step process automated" then you're headed in the right direction.
The point of the exercise
Vibe coding tools will change. The stack will change. The shiny thing will rotate again.
The skill you’re building is: taking an ambiguous desire and turning it into a shippable slice with constraints.
That is software engineering.
And it’s the part that doesn’t get obsoleted every time a new model drops.